The Facebook Page That Posts the Same Picture Every Day
On the Italian language version of Facebook, a curious page came into existence in latter half of 2014. This page is devoted to Toto Cutugno, an Italian singer and song-writer who is famous in the part of the world. Every day, the owner of this page posts a picture of Cutugno, indeed, the same picture every day.
This page is imaginatively entitled “La stessa foto di Toto Cutugno ogni giorno” meaning “The same photo of Toto Cutugno every day”. And it’s easy to imagine that it might attract little attention from the Facebook crowd.
Not so. The posts on this page have received almost 300,000 likes, 14,000 comments and been shared more than 7000 times. It’s fair to say it has a cult following, despite the homogeneity of its content.
That has piqued the interest of Alessandro Bessi at the Institute for Advanced Study in Pavia, Italy and few pals, who have made this page a central part of their research. These guys have been studying the way people consume content on social media sites and say that the Toto Cutugno page is the perfect control for their experiments.
The reasons are straightforward. Most of the pages this team is interested in host a wide range of different posts. These posts attract varying levels of interest in the form of likes, shares and comments. But exactly how this interest depends on the content is hard to tease apart.
What’s needed is a control page that always posts the same content so that the team can assess the background level of interest. Enter “La stessa foto di Toto Cutugno ogni giorno”. This page allows the team to see how users interact with a page when the content is held constant.
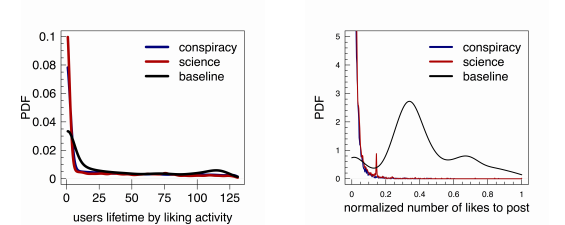
Bessi and co have compared the way people use this page with 73 public Facebook pages, 34 of them about science and 39 of them about conspiracy theories. They start by counting the number of likes for that each user gives to the pages visited. It turns out that this produces a power law or heavy-tailed distribution in which most users give a small number of likes while a few dish out a very large number. Curiously, the users of all the pages—the conspiracy theory pages, the science pages and the control page—follow this same pattern.
The team also looked at the lifetime of these users—for how long they continued to like pages. Once again the users of all pages follow a similar pattern, although users of the control page show some differences, such as more who continue to like the page for very long periods.
The big difference between the way people use these pages is in the number of likes each post receives. This follows a heavy tailed distribution for the conspiracy and science pages—so most pages receive a few likes but a few receive a great deal of them.
One of the features of this kind of distribution is that the concept of an “average” page makes no sense. In a normal distribution, the average coincides with the peak of the curve and so represents an important quantity about the data. This is useful when talking about the average height of adult men and women or their average weight and so on.
But there is no peak in a heavy-tailed distribution so the concept of an average makes no sense. That’s why people never talk about an average-sized earthquake or forest fire or flu outbreak, the sizes of which all follow heavy-tailed distributions.
That’s relevant because the way people “like” posts on the control page is entirely different to the way they “like” other posts. This follows something like a normal distribution in which there is a clear average number of likes.
That reveals something important about the way people like the control page—that the number of likes for any post clusters around some average value.
Just why this is the case, Bessi and co do not say. But it’s easy to speculate. The “La stessa foto di Toto Cutugno ogni giorno” page obviously attracts fans of the eponymous Cutugno, who are clearly limited in number. It is this limit that prevents any posts receiving the very large numbers of likes that are characteristic of a heavy tailed distribution.
Bessi and co go on to simulate the way people like each type of page and say they can capture this behaviour with a relatively simple model. “We show that the proposed model is able to reproduce the phenomenon observed from empirical data,” they say.
Just how useful this will be for future studies isn’t clear. Nevertheless, Cutugno himself must be flattered at the scientific attention his image has generated.
Ref: arxiv.org/abs/1501.07201 : Everyday the Same Picture: Popularity and Content Diversity
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.