The Emerging Science of Human-Data Interaction
Back in 2013, the UK supermarket giant, Tesco, announced that it was installing face recognition software in 450 of its stores that would identify customers as male or female, guess their age and measure how long they looked at an ad displayed on a screen below the camera. Tesco would then give the data to advertisers to show them how well their advertising worked and allow them to target their ads more carefully.
Many commentators pointed out the similarity between this system and the sci-fi film Minority Report in which people are bombarded by personalised ads which detect who they are and where they are looking.
It also raised important questions about data collection and privacy. How would customers understand the potential uses of this kind of data, how would they agree to these uses and how could they control the data after it was collected?
Now Richard Mortier at the University of Nottingham in the UK and a few pals say the increasingly complex, invasive and opaque use of data should be a call to arms to change the way we study data, interact with it and control its use. Today, they publish a manifesto describing how a new science of human-data interaction is emerging from this “data ecosystem” and say that it combines disciplines such as computer science, statistics, sociology, psychology and behavioural economics.
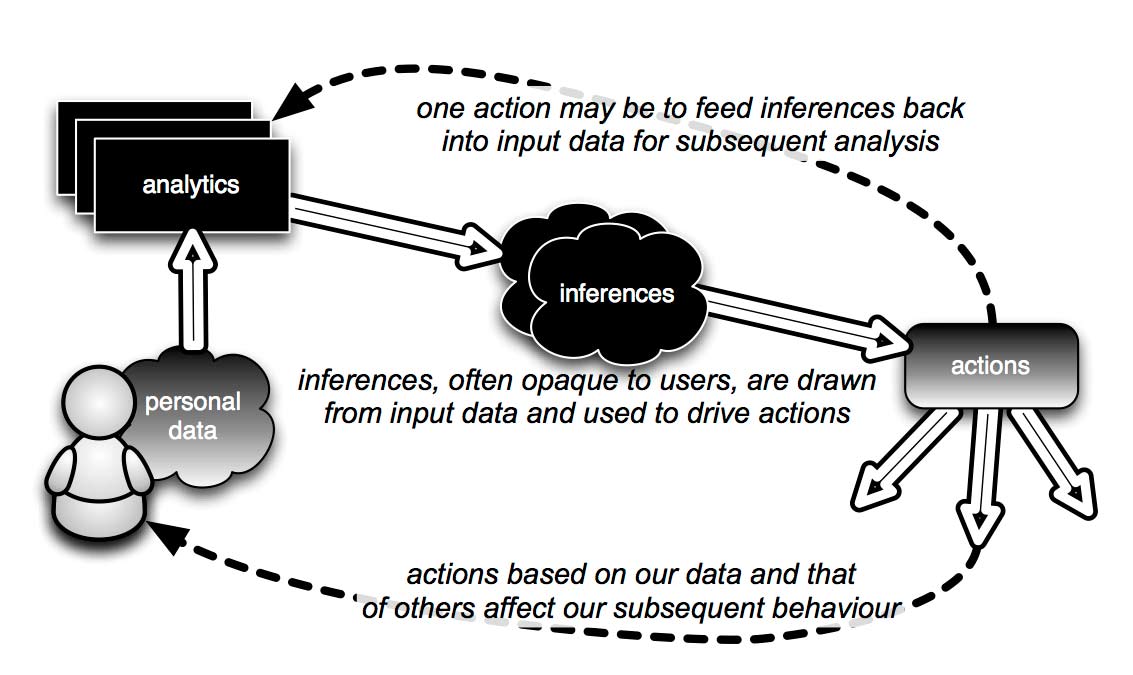
They start by pointing out that the long-standing discipline of human-computer interaction research has always focused on computers as devices to be interacted with. But our interaction with the cyber world has become more sophisticated as computing power has become ubiquitous, a phenomenon driven by the Internet but also through mobile devices such as smartphones. Consequently, humans are constantly producing and revealing data in all kinds of different ways.
Mortier and co say there is an important distinction between data that is consciously created and released such as a Facebook profile; observed data such as online shopping behaviour; and inferred data that is created by other organisations about us, such as preferences based on friends’ preferences.
This leads the team to identify three key themes associated with human-data interaction that they believe the communities involved with data should focus on.
The first of these is concerned with making data, and the analytics associated with it, both transparent and comprehensible to ordinary people. Mortier and co describe this as the legibility of data and say that the goal is to ensure that people are clearly aware of the data they are providing, the methods used to draw inferences about it and the implications of this.
Making people aware of the data being collected is straightforward but understanding the implications of this data collection process and the processing that follows is much harder. In particular, this could be in conflict with the intellectual property rights of the companies that do the analytics.
An even more significant factor is that the implications of this processing are not always clear at the time the data is collected. A good example is the way the New York Times tracked down an individual after her seemingly anonymized searches were published by AOL. It is hard to imagine that this individual had any idea that the searches she was making would later allow her identification.
The second theme is concerned with giving people the ability to control and interact with the data relating to them. Mortier and co describe this as “agency”. People must be allowed to opt in or opt out of data collection programs and to correct data if it turns out to be wrong or outdated and so on. That will require simple-to-use data access mechanisms that have yet to be developed
The final theme builds on this to allow people to change their data preferences in future, an idea the team call “negotiability”. Something like this is already coming into force in the European Union where the Court of Justice has recently begun to enforce the “right to be forgotten”, which allows people to remove information from search results under certain circumstances.
This is a tricky area but Mortier and co point out that the balance of power in the data ecosystem is weighted towards the collectors and aggregators rather than to private individuals and this needs to be redressed.
The overall impression from this manifesto is that our data-driven society is evolving rapidly, particularly with the growing focus on big data. An important factor in all this is the role of governments and, in particular, the revelations about data collection by government bodies such as the NSA in the US, GCHQ in the UK and even health providers such as the UK’s National Health Service.
“We believe that technology designers must take on the challenge of building ethical systems,” conclude Mortier and co.
That’s something Tesco and other data collectors would do well to bear in mind. But while this is clearly a worthy goal and one that there should be general and widespread support for, the devil will be in the detail. When it comes to building consensus, the words “herding” and “cats” come to mind.
Worth pursuing nevertheless.
Ref: http://arxiv.org/abs/1412.6159 : Human-Data Interaction: The Human Face of the Data-Driven Society
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.