Google’s Secretive DeepMind Startup Unveils a "Neural Turing Machine"
One of the great challenges of neuroscience is to understand the short-term working memory in the human brain. At the same time, computer scientists would dearly love to reproduce the same kind of memory in silico.
Today, Google’s secretive DeepMind startup, which it bought for $400 million earlier this year, unveils a prototype computer that attempts to mimic some of the properties of the human brain’s short-term working memory. The new computer is a type of neural network that has been adapted to work with an external memory. The result is a computer that learns as it stores memories and can later retrieve them to perform logical tasks beyond those it has been trained to do.
DeepMind’s breakthrough follows a long history of work on short-term memory. In the 1950s, the American cognitive psychologist George Miller carried out one of the more famous experiments in the history of brain science. Miller was interested in the capacity of the human brain’s working memory and set out to measure it with the help of a large number of students who he asked to carry out simple memory tasks.
Miller’s striking conclusion was that the capacity of short-term memory cannot be defined by the amount of information it contains. Instead Miller concluded that the working memory stores information in the form of “chunks” and that it could hold approximately seven of them.
That raises the curious question: what is a chunk? In Miller’s experiments, a chunk could be a single digit such as a 4, a single letter such as a q, a single word or a small group of words that together have some specific meaning. So each chunk can represent anything from a very small amount of information to a hugely complex idea that is equivalent to large amounts of information.
But however much information a single chunk represents, the human brain can store only about seven of them in its working memory.
Here is an example. Consider the following sentence: “This book is a thrilling read with a complex plot and lifelike characters.”
This sentence consists of around seven chunks of information and is clearly manageable for any ordinary reader.
By contrast, try this sentence: “This book about the Roman Empire during the first years of Augustus Caesar’s reign at the end of the Roman Republic, describes the events following the bloody Battle of Actium in 31 BC when the young emperor defeated Mark Antony and Cleopatra by comprehensively outmaneuvering them in a major naval engagement.”
This sentence contains at least 20 chunks. So if you found it more difficult to read, that shouldn’t be a surprise. The human brain has trouble holding this many chunks in its working memory.
In cognitive science, the ability to understand the components of a sentence and store them in the working memory is called variable binding. This is the ability to take a piece of data and assign it to a slot in the memory and to do this repeatedly with data of different length, like chunks.
During the 1990s and 2000s, computer scientists repeatedly attempted to design algorithms, circuits and neural networks that could perform this trick. Such a computer should be able to parse a simple sentence like “Mary spoke to John” by dividing it into its component parts of actor, action and the receiver of the action. So in this case, it would assign the role of actor to Mary, the role of action to the words “spoke to” and the role of receiver of the action to “John.”
It is this task that DeepMind’s work addresses, despite the very limited performance of earlier machines. “Our architecture draws on and potentiates this work,” say Alex Graves, Greg Wayne, and Ivo Danihelka at DeepMind, which is based in London.
They begin by redefining the nature of a neural network. Until now, neural networks have been patterns of interconnected “neurons” which are capable of changing the strength of the interconnections in response to some external input. This is a form of learning that allows them to spot similarities between different inputs.
But the fundamental process of computing contains an important additional element. This is an external memory which can be written to and read from during the course of a computation. In Turing’s famous description of a computer, the memory is the tickertape that passes back and forth through the computer and which stores symbols of various kinds for later processing.
This kind of readable and writable memory is absent in a conventional neural network. So Graves and co have simply added one. This allows the neural network to store variables in its memory and come back to them later to use in a calculation.
This is similar to the way an ordinary computer might put the number 3 and the number 4 inside registers and later add them to make 7. The difference is that the neural network might store more complex patterns of variables representing, for example, the word “Mary.”
Since this form of computing differs in an important way from a conventional neural network, Graves and co give it a new name—they call it a Neural Turing Machine, the first of its kind to have been built. The Neural Turing Machine learns like a conventional neural network using the inputs it receives from the external world but it also learns how to store this information and when to retrieve it.
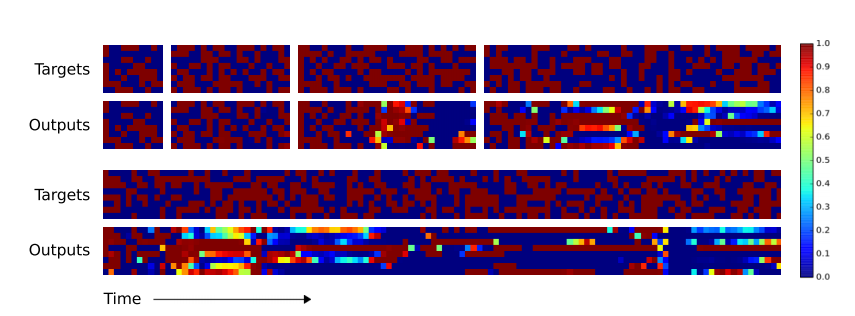
The DeepMind work involves first constructing the device and then putting it through its paces. Their experiments consist of a number of tests to see whether, having trained a Neural Turing Machine to perform a certain task, it could then extend this ability to bigger or more complex tasks. “For example, we were curious to see if a network that had been trained to copy sequences of length up to 20 could copy a sequence of length 100 with no further training,” say Graves and co.
It turns out that the neural Turing machine learns to copy sequences of lengths up to 20 more or less perfectly. And it then copies sequences of lengths 30 and 50 with very few mistakes. For a sequence of length 120, errors begin to creep in, including one error in which a single term is duplicated and so pushes all of the following terms one step back. “Despite being subjectively close to a correct copy, this leads to a high loss,” say the team.
Although the sequences involved are random, it’s not hard to imagine how they might represent more complex ideas such as “Mary” or “spoke to” or “John.” An important point is that the amount of information these sequences contain is variable, like chunks.
They compare the performance of their Neural Turing Machine with a conventional neural network. The difference is significant. The conventional neural network learns to copy sequences up to length 20 almost perfectly. But when it comes to sequences that are longer than the training data, errors immediately become significant. And its copy of the longest sequence of length 120 is almost unrecognizable compared to the original.
The DeepMind team go on to test the Neural Turing Machine on other tasks. For example, one of these is the equivalent of photocopying: the task is to copy a sequence and then repeat that sequence a specified number of times and end with a predetermined marker. Once again, the Neural Turing Machine significantly outperforms a conventional neural network.
That is an impressive piece of work. “Our experiments demonstrate that [our Neural Turing Machine] is capable of learning simple algorithms from example data and of using these algorithms to generalize well outside its training regime,” say Graves and co.
That is an important step forward that has the potential to make computing machines much more brainlike than ever before. But there is significant work ahead.
In particular, the human brain performs a clever trick to make sense of complex arguments. An interesting question that follows from Miller’s early work is this: if our working memory is only capable of handling seven chunks, how do we make sense of complex arguments in books, for example, that consists of thousands or tens of thousands of chunks?
Miller’s answer is that the brain uses a trick known as a recoding. Let’s go back to our example of the book and add another sentence: “This book is a thrilling read with a complex plot and lifelike characters. It is clearly worth the cover price.”
Once you have read and understood the first sentence, your brain stores those seven chunks in a way that is available as a single chunk in the next sentence. In this second sentence, the pronoun “it” is this single chunk. Our brain automatically knows that “it” means: “the book that is a thrilling read with a complex plot and lifelike characters.” It has recoded the seven earlier chunks into a single chunk.
To Miller, the brain’s ability to recode in this way was one of the keys to artificial intelligence. He believed that until a computer could reproduce this ability, it could never match the performance of the human brain.
Google’s DeepMind has stated that its goal is “solving intelligence.” If this solution is anything like human intelligence, a good test would be to see whether Neural Turing Machines are capable of Miller’s recoding trick.
Ref: arxiv.org/abs/1410.5401 : Neural Turing Machines
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.