The Emerging Pitfalls Of Nowcasting With Big Data
Earlier this year, the European Central Bank held a two-day workshop on big data and how it can be used for forecasting. The headline speaker was Hal Varian, chief economist at Google and a number cruncher of rock star status.
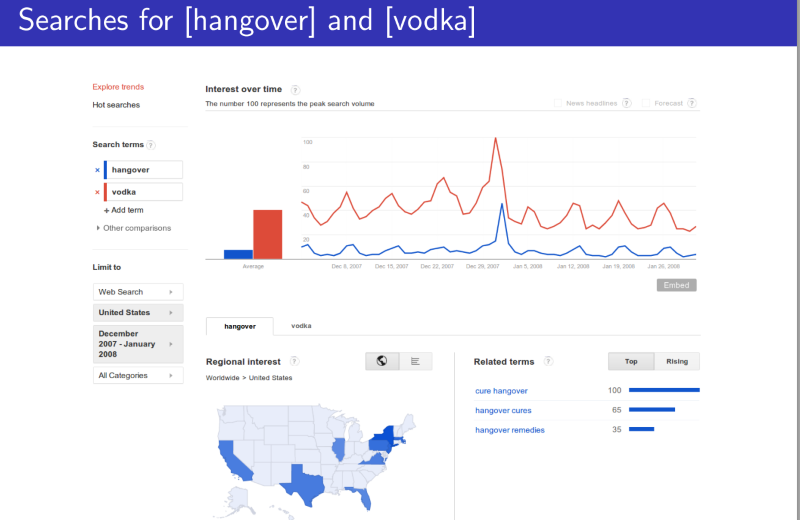
Varian outlined the power of Google Trends and Google Correlate, the company’s big data tools. “With Google Trends, you type in a query and get back a data series of activity. With Google Correlate, you enter a data series and get back a list of queries whose data series follows a similar pattern,” says Google on its Correlate website. In other words Google Correlate is like Google Trends in reverse.
Varian showed all kinds of interesting trends and correlations. For example, searches for the word “hangover” rise substantially on a Saturday, peak on a Sunday and drop off markedly on a Monday. And the pattern is similar to the pattern of searches for the word “vodka,” albeit lagging by a day (or more likely, a night and a morning after).
In another example, he showed how entering the data on initial claims for unemployment benefits in the US returned a list of 100 queries that followed a similar pattern including the phrase ”sign up for unemployment.”
There are limits of course. He showed a spurious correlation between US auto sales and the search query “Indian restaurants” between 2004 and 2012. Just why these two datasets follow similar trends is not clear but as any statistician will tell you correlation does not mean causation.
The message was clear. Search query data is hugely powerful but must be treated with some care and caution.
Today, Paul Ormerod from University College London and a couple of pals say there are other reasons to be cautious. These guys have studied Google Flu Trends data in which Google uses the number of flu-related searches to nowcast the incidence of flu in different parts of the world at any particular time.
Ormerod and co say there are several impressive examples where Google has accurately estimated the number of flu cases, for example in the US in 2011/12, Switzerland 2007/8, Germany 2005/6 and Belgium 2007/8. This ability to monitor flu has received widespread media attention.
Less well-known are the cases where Google Trends significantly overestimated the actual number of flu cases. This occurred in the US during the winter of 2012/13, in Switzerland in 2008/9, Germany in 2008/9 and Belgium in 2008/9.
Why the difference? Ormerod and co hypothesise that people making flu-related searches fall into two categories. The first are those suffering symptoms of flu and the second group are searching merely because other people are searching too, perhaps because of strong media interest in flu for example.
Of course, the useful data comes from the first group who are flu sufferers. Their reason for searching is internally generated and independent of the external world—they’re feeling ill. So their pattern of searches should be different from people who are searching because of external influences like newspaper reports. This process of social searching simply serves to inflate the numbers.
So how to tell these two groups apart? Ormerod and co hypothesise that the pattern of independent searches over time will differ substantially from social searches. In particular, they say that independent searches ought to rise rapidly as flu sweeps through the population and decline slowly as the disease dies out. By contrast, social searches are more symmetrical.
So the symmetry in the data is a measure of the level of social searching. Indeed, they show that this symmetry is clearly more evident in the years when Google Flu Trends substantially overestimated cases compared with years when it was more accurate.
That’s an interesting example of the kinds of pitfalls that statisticians must negotiate when analysing big data. Google Trends is merely an example—the world is increasingly awash with big data sets and with statisticians licking their lips.
There’s no question that important information relating to economics, health and other things can be extracted from big data given the right tools. But exactly how this should be done accurately and reliably is still the subject of significant debate.
That’s not entirely different from the situation that exists with current economic data, which generally lags the real economy by at least a month and is often revised later when the figures are clearer. The unreliability of these figures as a source of considerable concern for policymakers.
It seems clear that government agencies, companies and almost anyone willing to play with the numbers will be able to extract significant value from search query data in future.
But be warned, considerable care is needed. It’s not just vodka that leaves a nasty taste in the mouth the following morning. Many an economic hangover has been caused by over-indulgence in unreliable data.
Ref: arxiv.org/abs/1408.0699 : Nowcasting Economic And Social Data: When And Why Search Engine Data Fails, An Illustration Using Google Flu Trends
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.