How Advanced Socialbots Have Infiltrated Twitter
If you have a Twitter account, the chances are that you have fewer than 50 followers and that you follow fewer than 50 people yourself. You probably know many of these people well but there may also be a few on your list who you’ve never met.
So here’s an interesting question: how do you know these Twitter users are real people and not automated accounts, known as bots, that are feeding you links and messages designed to sway your opinions?
You might say that bots are not very sophisticated and so easy to spot. And that Twitter monitors the Twittersphere looking for, and removing, any automated accounts that it finds. Consequently, it is unlikely that you are unknowingly following any automated accounts, malicious or not.
If you hold that opinion, it’s one that you might want to revise following the work of Carlos Freitas at the Federal University of Minas Gerais in Brazil and a few pals, who have studied how easy it is for socialbots to infiltrate Twitter.
Their findings will surprise. They say that a significant proportion of the socialbots they have created not only infiltrated social groups on Twitter but became influential among them as well. What’s more, Freitas and co have identified the characteristics that make socialbots most likely to succeed.
These guys began by creating 120 socialbots and letting them loose on Twitter. The bots were given a profile, made male or female and given a few followers to start off with, some of which were other bots.
The bots generate tweets either by reposting messages that others have posted or by creating their own synthetic tweets using a set of rules to pick out common words on a certain topic and put them together into a sentence.
The bots were also given an activity level. High activity equates to posting at least once an hour and low activity equates to doing it once every two hours (although both groups are pretty active compared to most humans). The bots also “slept” between 10 p.m. and 9 a.m. Pacific time to simulate the down time of human users.
Finally, they were set up to follow one of three different groups of humans. The first consisted of 200 people randomly selected from the Twitter stream, the second was 200 people who regularly post tweets on a specific topic in this case software development, and the final group consisted of 200 software developers who were all socially connected to each other on Twitter.
Having let the socialbots loose, the first question that Freitas and co wanted to answer was whether their charges could evade the defenses set up by Twitter to prevent automated posting. “Over the 30 days during which the experiment was carried out, 38 out of the 120 socialbots were suspended,” they say. In other words, 69 percent of the social bots escaped detection.
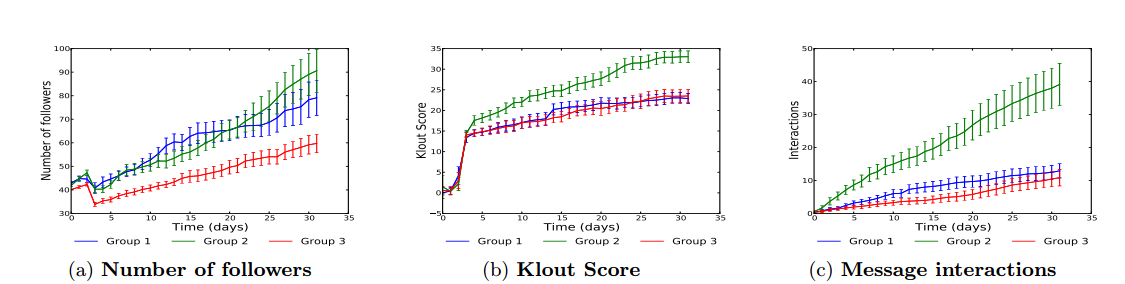
The more interesting question, though, was whether the social bots can successfully infiltrate the social groups they were set up to follow. And on that score the results are surprising. Over the duration of the experiment, the 120 socialbots received a total of 4,999 follows from 1,952 different users. And more than 20 percent of them picked up over 100 followers, which is more followers than 46 percent of humans on Twitter.
Freitas and co also monitored the Klout score of each of their social bots to see how they fared. (Klout is an online service that measures the influence of Twitter accounts, giving them a score between 0 and 100). “We find that the socialbots achieved Klout scores of the same order of (or, at times, even higher than) several well-known academicians and social network researchers,” they say.
The team also teased apart the data to find out what factors contributed to the success of the bots. Unsurprisingly, activity level is important and the more active bots achieved greater popularity in their social networks. That’s expected since more active bots are more likely to be seen by others (although they are also more likely to be detected by Twitter’s defense mechanisms).
More surprisingly, the socialbots that generated synthetic tweets (rather than just reposting) performed better too. That suggests that Twitter users are unable to distinguish between posts generated by humans and by bots. “This is possibly because a large fraction of tweets in Twitter are written in an informal, grammatically incoherent style, so that even simple statistical models can produce tweets with quality similar to those posted by humans in Twitter,” suggest Freitas and co.
The groups that the socialbots were set up to follow also had a major effect. The group of socially connected software developers produced the fewest followers while the group of randomly chosen software developers generated the highest number of them.
Gender also played a role. While male and female bots were equally effective when considered overall, female social bots were much more effective at generating followers among the group of socially connected software developers. “This suggests that the gender of the socialbots can make a difference if the target users are gender-biased,” say Freitas and pals.
That’s an interesting piece of work. It suggests that the Twittersphere may be more vulnerable to automated attack than previously thought.
It’s a finding that may have significant implications for certain types of groups on Twitter. In recent years a number of services have arisen to measure interest and opinion among Twitter users on a wide variety of topics, such as voting intention, product sentiment, disease outbreaks, natural disasters and so on.
The worry is that automated bots could be designed to significantly influence opinion in one or more of these areas. For example, it would be relatively straightforward to create a bot that spreads false rumors about a political candidate in a way that could influence an election.
So the work of Freitas and co is a wake-up call for Twitter. If it wants to successfully prevent these kinds of attacks, it will need to significantly improve its defense mechanisms. And since this work reveals what makes bots successful, Twitter’s research team has an advantage.
The trick will be to spot social bots and exclude them without mistakenly excluding human users in the process. That will be no easy task.
But with an estimated 20 million fake Twitter accounts already set up, Twitter’s researchers have plenty of data to work with.
Ref: arxiv.org/abs/1405.4927 : Reverse Engineering Socialbot Infiltration Strategies in Twitter
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.