The Emerging Science of Superspreaders (And How to Tell If You’re One Of Them)
Who are the most influential spreaders of information on a network? That’s a question that marketers, bloggers, news services and even governments would like answered. Not least because the answer could provide ways to promote products quickly, to boost the popularity of political parties above their rivals and to seed the rapid spread of news and opinions.
So it’s not surprising that network theorists have spent some time thinking about how best to identify these people and to check how the information they receive might spread around a network. Indeed, they’ve found a number of measures that spot so-called superspreaders, people who spread information, ideas or even disease more efficiently than anybody else.
But there’s a problem. Social networks are so complex that network scientists have never been able to test their ideas in the real world—it has always been too difficult to reconstruct the exact structure of Twitter or Facebook networks, for example. Instead, they’ve created models that mimic real networks in certain ways and tested their ideas on these instead.
But there is growing evidence that information does not spread through real networks in the same way as it does through these idealised ones. People tend to pass on information only when they are interested in a topic and when they are active, factors that are hard to take into account in a purely topological model of a network.
So the question of how to find the superspreaders remains open. That looks set to change thanks to the work of Sen Pei at Beihang University in Beijing and a few pals who have performed the first study of superspreaders on real networks.
These guys have studied the way information flows around various networks ranging from the Livejournal blogging network to the network of scientific publishing at the American Physical Society’s, as well as on subsets of the Twitter and Facebook networks. And they’ve discovered the key indicator that identifies superspreaders in these networks.
In the past, network scientists have developed a number of mathematical tests to measure the influence that individuals have on the spread of information through a network. For example, one measure is simply the number of connections a person has to other people in the network, a property known as their degree. The thinking is that the most highly connected people are the best at spreading information.
Another measure uses the famous PageRank algorithm that Google developed for ranking webpages. This works by ranking somebody more highly if they are connected to other highly ranked people.
Then there is ‘betweenness centrality’ , a measure of how many of the shortest paths across a network pass through a specific individual. The idea is that these people are more able to inject information into the network.
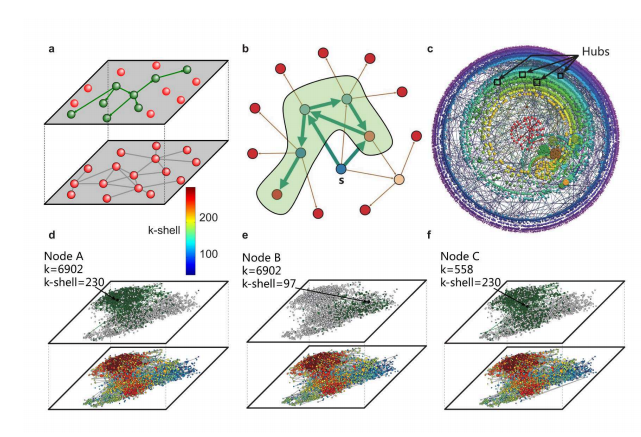
And finally there is a property of nodes in a network known as their k-core. This is determined by iteratively pruning the peripheries of a network to see what is left. The k-core is the step at which that node or person is pruned from the network. Obviously, the most highly connected survive this process the longest and have the highest k-core score..
The question that Sen and co set out to answer was which of these measures best picked out superspreaders of information in real networks.
They began with LiveJournal, a network of blogs in which individuals maintain lists of friends that represent social ties to other LiveJournal users. This network allows people to repost information from other blogs and to use a reference that links back to the original post. This allows Sen and co to recreate not only the network of social links between LiveJournal users but also the way in which information is spread between them.
Sen and co collected all of the blog posts from February 2010 to November 2011, a total of more than 56 million posts. Of these, some 600,000 contain links to other posts published by LiveJournal users.
The data reveals two important properties of information diffusion. First, only some 250,000 users are actively involved in spreading information. That’s a small fraction of the total.
More significantly, they found that information did not always diffuse across the social network. The found that information could spread between two LiveJournal users even though they have no social connection.
That’s probably because they find this information outside of the LiveJournal ecosystem, perhaps through web searches or via other networks. “Only 31.93% of the spreading posts can be attributed to the observable social links,” they say.
That’s in stark contrast to the assumptions behind many social network models. These simulate the way information flows by assuming that it travels directly through the network from one person to another, like a disease spread by physical contact.
The work of Sen and co suggests that influences outside the network are crucial too. In practice, information often spreads via several seemingly independent sources within the network at the same time. This has important implications for the way superspreaders can be spotted.
Sen and co say that a person’s degree– the number of other people he or her are connected to– is not as good a predictor of information diffusion as theorists have thought. “We find that the degree of the user is not a reliable predictor of influence in all circumstances,” they say.
What’s more, the Pagerank algorithm is often ineffective in this kind of network as well. “Contrary to common belief, although PageRank is effective in ranking web pages, there are many situations where it fails to locate superspreaders of information in reality,” they say.
By contrast, the k-core property is a relatively good at finding superspreaders. “We consistently find that the best spreaders are located in the k-core,” they say.
What’s interesting here is that Sen and co found similar results when they examined the network of scientific dissemination in journals of the American Physical Society as well as in subsets of the networks on Twitter and Facebook. Users of all these different networks showed the same information-spreading behaviour.
But before you conclude that the problem of finding superspreaders is now solved, there is an additional factor that needs to be taken into account. The k-core measure is a global property of the network–it can only be calculated by taking into account the structure of entire network.
That’s not so convenient when it comes to large networks, such as Facebook and Twitter, which are also the most valuable for marketers, politicians and so on.
So Sen and co have developed yet another measure of influence which works almost as well as the k-core measure but is much easier to calculate using on subsets of the entire network.
Their method is to sum the degrees of a person’s nearest neighbours and say this is almost as good as the k-core score at predicting superspreaders.
In other words, take each of your closest friends, count the number of connections they have and then add them all together. If your closest friends are all highly connected, the chances are that you are a superspreader.
If so, there are a few people who’d like to get to know you better—marketers, politicians, governments and so on. With superspreaders being such valuable commodities, it’ll be interesting to see how the market for them and their services evolves.
Ref: arxiv.org/abs/1405.1790 : Searching For Superspreaders Of Information In Real-World Social Media
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.