Tweets Have Become Shorter Since 2009, Say Computer Scientists
Back in the old days, say in 2009, Twitter was a relatively unknown social network that was beginnign to spread like wildfire. In 2007, Twitter users posted some 400,000 tweets per quarter, by June 2010, they were posting 65 million each day. Today, there are 200 million registered users who send around 400 million tweets every day.
During this short time, Twitter has become so popular that its technical argot has entered the common language. Words like hashtag and @name would have seemed little more than gibberish just a few years ago. But even the word tweet is now a verb officially recognised in the Oxford English Dictionary.
Now evidence is emerging that Twitter may be having a more profound impact on the way we communicate. Today, Christian Alis and May Lim at the University of the Philippines say they have measured how the length of tweets have changed between September 2009 and December 2012 and say that tweets have shrunk dramatically in that time. “People are communicating with fewer and shorter words,” they say, almost certainly because we’re all using jargon more effectively.
They’ve also studied how the length of tweets varies geographically in the US from state to state. And they’ve looked to see how the changes correlate with various socio-economic statistics from the US Census Bureau. The results are surprising.
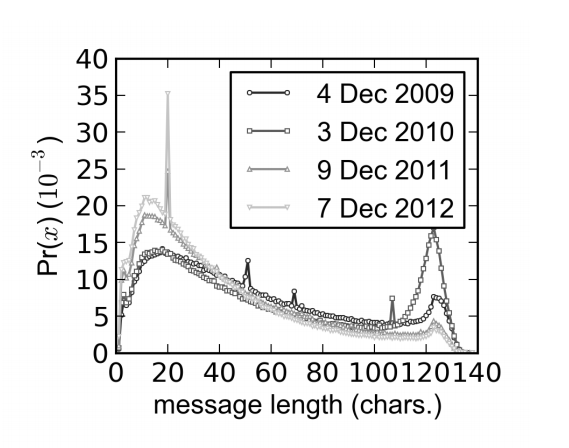
First, more about the study itself. Alis and Lim collected 229 million tweets published between 18 September 2009 and 14 December 2012. They then counted the length of each tweet and plotted this against the date of publication.
The data is interesting. The distribution of tweet lengths has two peaks. One is near the 140 character limit for tweets, which Allis and Lam interpret as a forced constraint. In other words, tweeters can’t send messages longer than this, even if they want to, and so are forced to end their messages at this length.
The second peak is what varies over time. Between November 2009 and December 2012, Alis and Lim say the median utterance length in words decreased from 8 words to 5 words
This shortening is a global phenomenon which is true for the dataset as a whole, for tweets in English alone and even when all the links are removed from the dataset.
(In October 2011, Twitter introduced a link-shortening algorithm that converts all URLs into 20 character addresses. This causes a spike in words that are 20 characters in length but doesn’t change the trend towards shorter tweets.)
Having found this curious shortening effect. Alis and Lim ask what might be causing it. “The shortening, it seems, can be explained by increased usage of jargon,” they say.
That’s significant because it implies that Twitter users are becoming segregated into well-defined groups of those who understand the same jargon.
In a curious twist, Alis and Lim also study the subset of 800,000 tweets that are geotagged with a US state. They say the numbers of tweets from each state are strongly correlated with the population of that state as recorded in the 2010 census.
In plotting the length of utternaces on a map of the US, a clear geographical trend becomes obvious. “Southeastern and eastern US states tend to have shorter utterance lengths,” they say. Just why this is the case isn’t clear.
Alis and Lim go on to check for correlations with 51 variables measured in the 2010 census and now published online. These are factors like “Persons 25 years and over who are high school graduates or higher from 2007 to 2011 in percent” or “Owner-occupied housing units in percent of total occupied housing units from 2007 to 2011” or “2011 resident Black population in percent”.
It turns out that the only variable that correlates strongly with shorter utterances is Black population percentage. Why this should be isn’t clear but Alis and Lim point out that there is evidence that the black population uses Twitter significantly more than other groups and that jargon may be more common in this group.
Of course correlation does not imply causality. One way to study this in more detail would be to examine the content of the tweets in detail. But Alis and Lim say this is beyond the scope of their study.
What’s interesting about this work is that conversations reflect the existing norms of a language. So any evidence of change is significant. It may be that we’re all using much more jargon in our tweets and that this represents a fundamental change in the way we communicate. Then again, we may just be learning how to use Twitter more efficiently. At some level, perhaps those things are even equivalent.
Your views, please, in the comments section.
Ref: arxiv.org/abs/1310.2479: Spatio-Temporal Variation of Conversational Utterances On Twitter
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.