Human Brain Is Limiting Global Data Growth, Say Computer Scientists
In the early 19th century, the German physiologist Ernst Weber gave a blindfolded man a mass to hold and gradually increased its weight, asking the subject to indicate when he first became aware of the change. Weber discovered that the smallest increase in weight a human can perceive is proportional to the initial mass.
This is now known as the Weber-Fechner law and shows that the relationship between the stimulus and perception is logarithmic.
It’s straightforward to apply this rule to modern media. Take images for example. An increase in resolution of a low resolution pictue is more easily perceived than the same increase to a higher resolution picture.
When two parameters are involved, the relationship between the stimuli and perception is the square of the logarithm. An example would be video in which images change with time.
This way of thinking about stimulus and perception clearly indicates that the Weber-Fechner law ought to have a profound effect on the rate at which we absorb information.
Today, Claudius Gros and a couple of pals at Goethe University Frankfurt in Germany look for signs of the Weber-Fechner law in the size distribution of files on the internet. And they say they’ve found them.
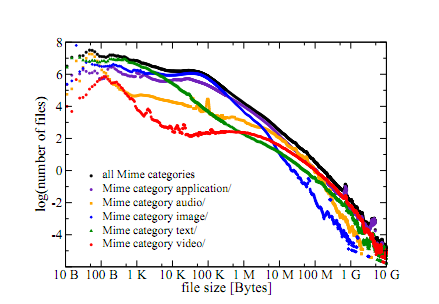
These guys measured the type and size of files pointed to by every outward link from Wikipedia and the open directory project, dmoz.org. That’s a total of more than 600 million files. Some 58 per cent of these pointed to image files, 32 per cent to application files, 5 per cent to text files, 3 per cent to audio and 1 per cent to video files.
Gros and co then plotted the size of each of these files types against the number of files to get the file size distribution.
Sure enough, they discovered that the audio and video file distribution followed a log-normal curve, which is compatible with a logarithmic squared-type relationship. By contrast, image files follow a power law distribution, which is compatible with a logarithmic relationship. That’s exactly as the Weber-Fechner law predicts
“[This] strongly indicates that [the distributions] are determined by the underlying neurophysiological limitations of the producing agents,” say Gros and co. In other words ‘us’.
Further evidence comes from a closer look at the tails of these curves. If the size of files were determined by some kind of economic factor, like the cost of producing a file, then the distribution ought to have an exponential tail. But that’s not the case. The absence of this feature suggests some other origin for the file size distribution.
Gros and co put it like this: “The neuropsychological capacity of the human brain to process and record information may constitute the dominant limiting factor for the overall growth of globally stored information, with real-world economic constraints having only a negligible influence.”
Quite! In other words, global information cannot grow any faster than our ability to absorb or monitor it.
That makes sense and raises some interesting avenues for future research too. For example, it’ll be interesting to see how machine intelligence might change this equation. It may be that machines can be designed to distort our relationship with information.
If so, then a careful measure of file size distribution could reveal the first signs that intelligent machines are among us!
Ref: arxiv.org/abs/1111.6849: Neuropsychological Constraints To Human Data Production On A Global Scale
12 December 2011: updated to correct the spelling of the the Weber-Fechner law. Thanks Gavin Owens!
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.