The Unexpected Ubiquity of Spam Detection Algorithms
If you want to find out if two spam emails are identical without comparing every single byte in them – which would take an undue amount of time – you digest the file into a short string, known as a cryptographic hash value. It’s in the nature of a cryptographic hash function that even the tiniest change in a file will yield a wildly different hash value, so it’s easy to tell if two files are identical.
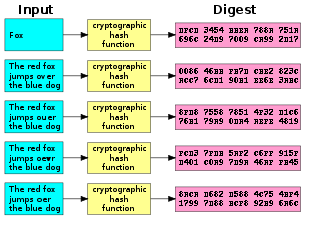
This may sound trivial, but it’s not: if you already have an example of an undesirable file – say a piece of spam email – and you want to compare it pairwise to millions of other emails streaming through your servers, you need to be able to identify it quickly. Comparing 40 digit strings is significantly easier than reading millions of penis pill emails all the way through.
The problem with cryptographic hash functions is that even the tiniest change in the source file yields a hash value that’s completely different. In other words they’re useless for comparing files that may be functionally identical but only a little bit different.
One solution to this problem is what’s known as a fuzzy hash, or a rolling hash: instead of just hashing the entire file, the algorithm “provide[s] a continuous stream of hash values for a rolling window over the binary [of the original file],” says David French, a senior researcher at Carnegie Mellon’s Software Engineering Institute.
By comparing a bunch of hashes from two files, you can determine the percentage difference between them.
An Approach That Generalizes to… Everything?
This is where fuzzy hashing becomes really useful: suddenly, you’ve got a general purpose method for rapidly comparing any stream of information.
So you see fuzzy hashes cropping up all over the place. Here’s an effort by the aforementioned Dr. French to use fuzzy hashes to rapidly determine whether a file on a user’s computer is a virus or other piece of malware. And here’s an attempt to use fuzzy hashes to compare the draft gene sequence of one microorganism to a known sequence from a related creature. This is huge for geneticists, for whom the fastest way to assemble a reasonably accurate genome from a previously un-sequenced creature is to compare the sequenced fragments of its genes to a known sequence.
And have you ever wondered how Google detects duplicate content so that it can deliver to you only the most relevant results, instead of the hundreds of copies of a news article or reference work that inevitably end up on splogs spread across the Internet? Fuzzy hashing, again! It can even detect identical documents that are stored in completely different formats:
*A frequent case is that of the same document but in different formats; in these cases we will have completely different documents at binary level. The obvious solution is to compare plain text conversions of all these formats, but these conversions are never identical, because of the different treatments of the converters on various formatting elements (treatment of textual characters, diacritics, spacing, paragraphs …). In this work we introduce the possibility of using what is known as fuzzy-hashing. The idea is to produce fingerprints of files (or documents, etc..). This way, a comparison between two fingerprints could give us an estimate of the closeness or distance between two files, documents, etc.
Hell, you can tell just how important fuzzy hashing is because Michael Gregory Hoglund of Monte Sereno, CA just received an all-encompassing patent on the process, which he calls “generating a digital DNA sequence” for a data object. Before you know it, a patent troll will have bought this one off of Hoglund, and then the real fun can begin.
Fuzzy hashes are one of those invisible pieces of plumbing, like the MapReduce algorithm invented by Google that underpins practically every giant web service you can think of, that is critical to the operation of the global hive-mind on which we depend.
Anytime a computer must ask, “Which of these things is not like the other?” The answer is: Ask a fuzzy hash function!
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.